From frustrating lag to coding swag: discover how to turn a sluggish app into a speed demon with some clever performance hacks.
Author: Bartosz Słysz

Date added: 2025-01-07
8 min reading
Throughout my time in web development, I've heard multiple times that theoretical Computer Science is mostly useless when it comes to building real software. This is especially common in the front-end world, where frameworks handle most of the heavy lifting, and we often don't feel the need to dive deep into the underlying theory.
And yeah – I get it (sort of). When you're deep into the weeds of business logic, it can be hard to stick to the best patterns. Most of the time, it feels like just "getting it done" is the quickest path to results, and that's perfectly fine, especially when you're just looking to get things up and running.
But then, problems start popping up. When parts of the app begin to slow down, it can get frustrating. And if you're dealing with certain types of apps (e-commerce, I'm looking at you), that lag can really turn users off and hurt your bottom line.
In this article, we'll explore a few tricks that might just give your app a much-needed speed boost. I'm not claiming these are the ultimate solutions, or that you should blindly apply them everywhere. The goal here is to help you recognize useful patterns and develop a better instinct for writing faster, more efficient code.
Alright, let's roll! 🤸♂️
Matching data – one mistake at a time
If you've ever dipped your toes into Computer Science, you've definitely been through time complexity. You know the drill: classes start with sorting algorithms, usually kicking off with bubble sort, and then it's all about counting operations and figuring out how long it takes to get the job done. By the end, there's always a mention of the "cooler" algorithms like quicksort that can speed things up (though fun fact: quicksort is not always the fastest guy).
Sorting is a total cliché example, so let's switch gears to something more practical. In my experience, time complexity issues often pop up in the most unexpected places: those sneaky spots in your code you'd never think to double-check. Honestly, they're lurking around more corners than you'd imagine. I've been catching plenty of them during code reviews. Let me show you what I mean.
The problem: Tying together data from different sources
Imagine this: we've got two datasets – say, songs and their authors. Most of the time, the heavy lifting of matching these up is handled by the database. A quick JOIN statement here, some magical optimization with indexes there and bang: everything is blazing fast. frontend devs just get the data handed to them on a silver platter and call it a day.

But what happens, when for some reason, the backend can't handle the matching? Let's say that pagination isn't an option, and the backend doesn't want to send duplicate data (like the same song author popping up in the response multiple times). Instead, backend devs just say: here's a reference to the author, go find them yourself in the other dataset.
Sure, the plan sounds simple: push the extra work to the frontend, make the code more complex, but keep the response payload nice and lean – an easy trade-off, right?
Uhh ok, I'm just gonna wing it?
Let's bring back the cat from the last section for a while. And just like that – it spat out this code:
type Author = { name: string; id: number; };
type Song = { title: string; authorId: number; };
const generateAuthors = (amount: number) => (
[...Array(amount).keys()].map((idx) => ({
// totally not a fangirl move...
name: `Sabrina Carpenter #${idx}`,
// I'm brave enough to claim we don't have collisions here
id: Math.round(Math.random() * 100_000) + 1,
} satisfies Author)
));
const generateSongs = (amount: number, authors: Author[]) => (
[...Array(amount).keys()].map((idx) => ({
title: `taste.js ${idx}`,
authorId: authors[Math.floor(Math.random() * authors.length)].id,
} satisfies Song))
);
const matchAuthorsWithSongs = (authors: Author[], songs: Song[]) => (
songs.map(({ authorId, ...song }) => ({
...song,
author: authors.find(({ id }) => authorId === id),
}))
);
const authors = generateAuthors(10);
const songs = generateSongs(10, authors);
console.time();
matchAuthorsWithSongs(authors, songs);
console.timeEnd();
At first glance, it looks okay-ish. The algorithm does its thing: matches authors with songs, and it's pretty fast. On my machine, it clocks in at about 0.1ms to get the result. Not bad and sounds pretty promising, doesn't it? Let's throw some heavier datasets at it and see how it holds up.
const authors = generateAuthors(10_000);
const songs = generateSongs(10_000, authors);
console.time();
matchAuthorsWithSongs(authors, songs);
console.timeEnd();
And... oof, now we're talking 200ms. That's 2000x slower than before, and that hits me right in the heart. This is the moment where those old CS class flashbacks kick in, the ones with those scary graphs that shoot up as your dataset grows.
Turning a Simple Problem into a Masterpiece
Let's break it down and see what the complexity worst-case scenario for this algorithm actually looks like.
const matchAuthorsWithSongs = (authors: Author[], songs: Song[]) => (
// iterates over songs: O(songs.length)
songs.map(({ authorId, ...song }) => ({
...song,
// finds the author: O(authors.length) for each song
author: authors.find(({ id }) => authorId === id),
}))
// total complexity: O(songs.length * authors.length)
);
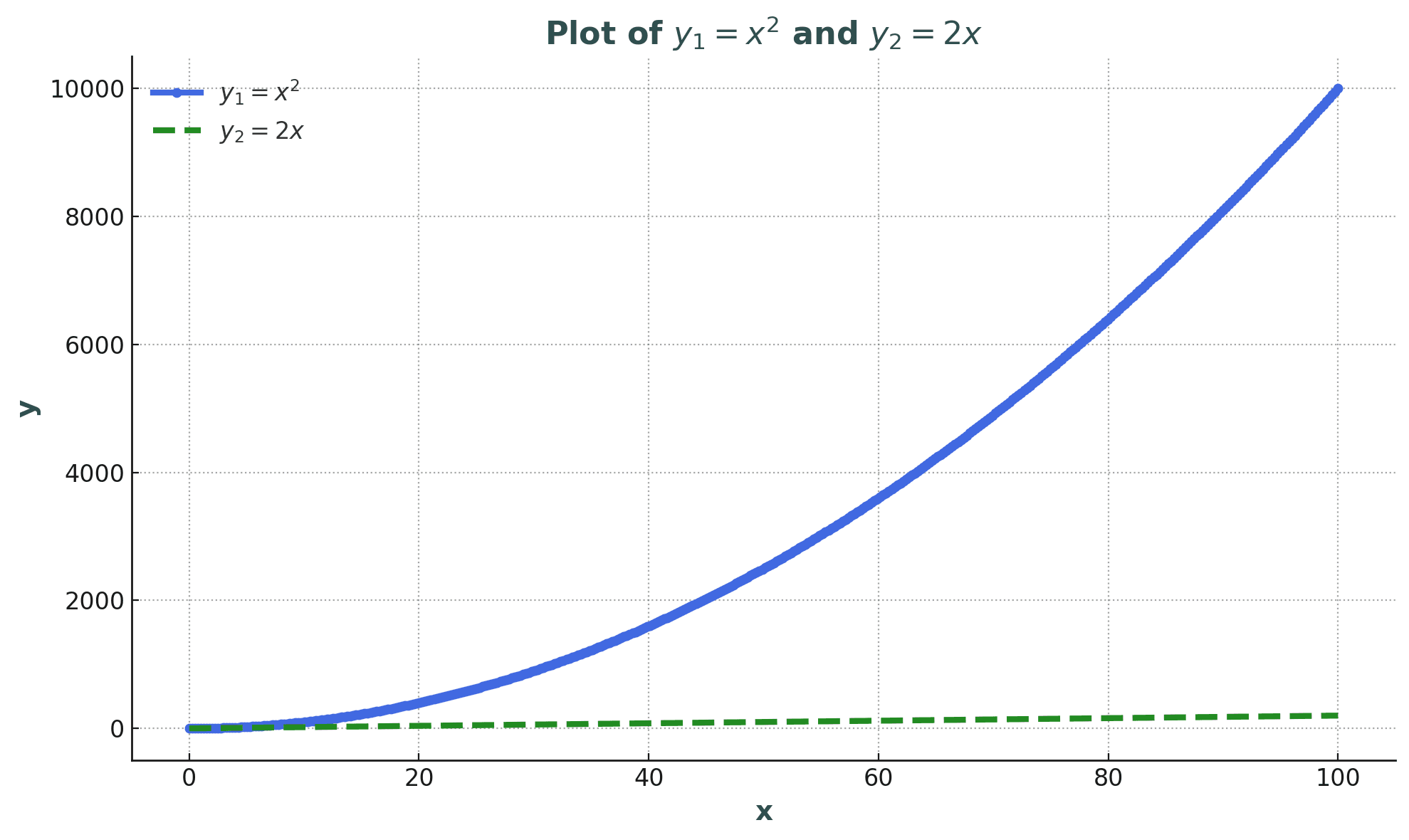
When authors and songs are about the same size, we're looking at O(n^2) complexity here and yeah, that should definitely set off some alarm bells. Especially when n starts getting big. So, can we do better? Absolutely, let me show you how.
const matchAuthorsWithSongs = (authors: Author[], songs: Song[]) => {
// first – create a map: { [authorId]: Author }
// complexity: O(authors.length)
const authorsById = authors.reduce((result, author) => {
result.set(author.id, author);
return result;
}, new Map<number, Author>);
// second – iterate over songs
// complexity: O(songs.length)
return songs.map(({ authorId, ...song }) => ({
...song,
// complexity (until we face hashmap collisions): O(1)
author: authorsById.get(authorId),
}));
// total complexity: O(authors.length + songs.length)
};
const authors = generateAuthors(10_000);
const songs = generateSongs(10_000, authors);
console.time();
matchAuthorsWithSongs(authors, songs);
console.timeEnd();
The average result on my machine comes in at about 6ms. Sure, that's still a decent amount of time, especially with larger numbers, but hey: it's nearly 35x faster (for that amount of data) than the previous method and scales way way better!
But still, we made some solid progress. A 200ms calculation on the main thread? Yeah, that's a hard pass. But 6ms? Eh, it's... fine, I guess. Nevertheless, I'll be honest with you: databases are still the champs here: with their superhuman algorithms, they can match things way faster.
By the way, backend developers working with GraphQL face a similar headache with the N+1 query problem. They often rely on the data loaders to optimize the process, because making things run efficiently is never as straightforward as it should be.
The Hash Map Hustle – speed demystified
Hash maps thrive on efficiency. They use a hash function to turn your key into a number, pointing directly to a bucket in an array. This avoids any unnecessary searching, keeping operations fast and direct.
Collisions (where two keys hash to the same bucket) are also part of the game. When this happens, both keys and values share the space. It's not ideal, but it works without sacrificing much speed. For lookups, the process repeats: hash the key, locate the bucket, and retrieve the value. Compared to other data structures, hash maps don't waste time. They're built for speed and nothing else.
Watch out for nesting array methods like they're the sneaky little troublemakers they are. Be skeptical when you see them, and when you absolutely can't avoid them, try to think about the complexity. This is especially important if the part of the app is used all over the place or deals with a ton of data. Sometimes, they hide as silent ninjas: e.g. when your React component uses [].find, but its parent is using [].map to render it along with a bunch of other siblings, and suddenly you're looking at... surprise surprise – O(n^2).
Dealing with data that refuses to sit still
Imagine building a platform for gamblers or more accurately – speculators. The kind of people who thrive on markets that are always shifting, like stock prices. And by the way – it's not a coincidence that trading apps are written in low-level languages for speed and hosted right next to Wall Street. In that world every millisecond matters.
Creating a real-time betting wonderland
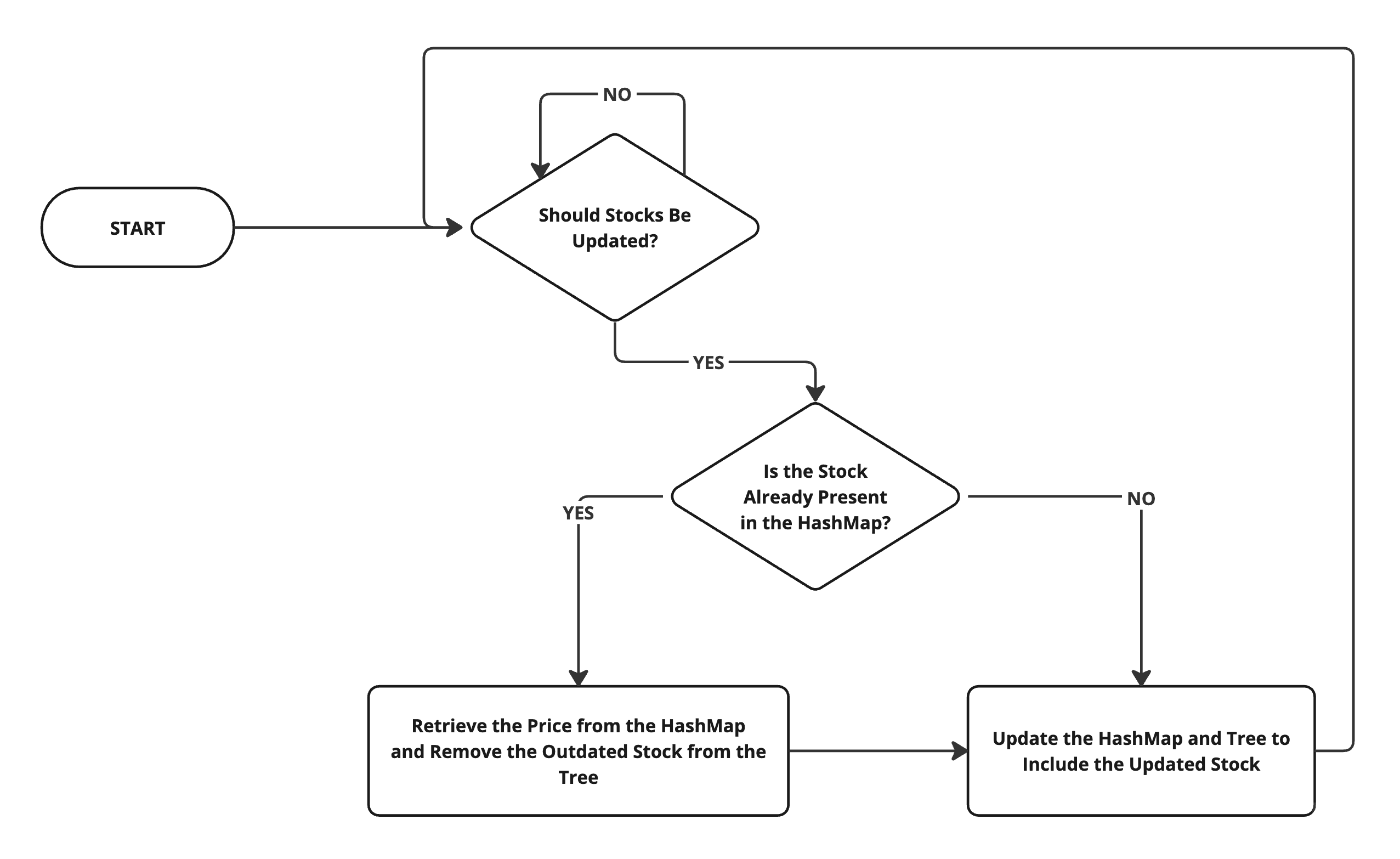
The frontend app needs to display a table with initial data from the backend, but it doesn't stop there. Updates come through in real time. Whenever a stock price changes, we get an update via websockets, containing the stock's ID and the new details. This keeps everything live and up-to-date.
Here's a simplified example along with time complexity notes described in the previous section:
type Stock = { idx: number; stockName: string; price: number; };
const generateStocks = (amount: number) => (
[...Array(amount).keys()].map((idx) => ({
idx: idx + 1,
stockName: `stock #${idx + 1}`,
price: Math.random(),
} satisfies Stock))
);
let sortedStocks = (
generateStocks(50_000).sort((a, b) => a.price - b.price)
);
const updateStock = (updatedStock: Stock) => {
sortedStocks = sortedStocks
// time complexity: O(n)
.map((item) => (
item.idx === updatedStock.idx ? updatedStock : item
))
// time complexity O(n log n)
.sort((a, b) => a.price - b.price)
// total complexity: O(n) + O(n log n) ~= O(n log n)
};
console.time();
updateStock({
...sortedStocks[25000],
price: Math.random(),
});
console.timeEnd();
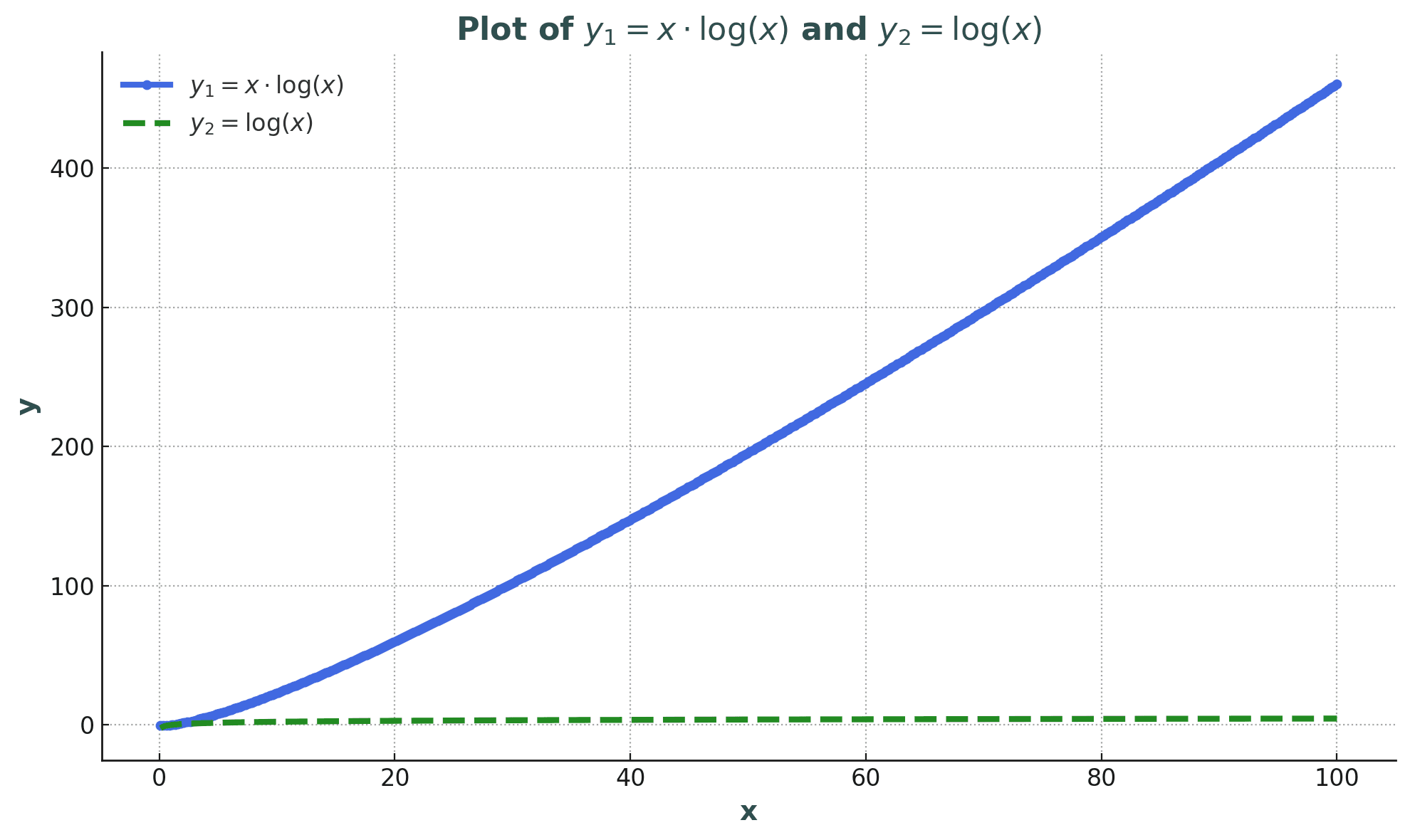
So, we have this updateStock function that takes an idx to update and some partial info about the stock (usually just the price). On my machine, for 50k elements, it takes around 5ms to update, which doesn't sound too terrifying – yet. When you think about updates streaming multiple times a second, that can quickly escalate into a serious issue.
Now, in typical UI apps, this wouldn't be a huge deal. We can usually apply some tricks, like batching changes each second, instead of handling each individual update. But remember – this is a gambling app, and every millisecond counts. So we really need to make sure we're as fast as possible.
Why settle for slow? Enter the Binary Trees
Now that we've managed to hit O(n log n) complexity, let's see if we can squeeze even more juice out of this. The task here is pretty focused: we're really only interested in the price field, which happens to be numeric.
And when I think "efficient data structure for numbers", my brain screams binary trees. In our case, we care about the price as the key, so why not use it to represent the stock's full details?
Binary trees are structured data containers where each node splits into at most two branches – left for smaller values, right for larger. This setup makes operations like searching, adding, or removing items swift, akin to flipping through an alphabetically sorted directory. They're practical in scenarios like organizing hierarchical data, such as a file system where folders contain other folders.
The functional-red-black-tree library, with around 8 million weekly downloads on NPM, implements red-black trees, which automatically rebalance themselves. This makes it an awesome solution for managing data around sorted, numeric values, turning what would be O(n) operations into O(log n), thus making algorithms super scalable. Numerous packages depend on this library for its efficiency in data organization and retrieval, ensuring performance doesn't degrade with dataset size.
Here's the snag, though: red-black trees (and other variations of binary trees) aren't exactly built to handle duplicate keys. So, we're left with two options: either find a workaround or accept this limitation as part of the deal.
For simplicity (and our own sanity), let's assume prices are unique in our stock-obsessed gambling den: no two stocks share the same value. With that out of the way, let's dive into how binary trees can bring some order to the chaos.
import createRBTree from "functional-red-black-tree";
type Stock = { idx: number; stockName: string; price: number; };
const generateStocks = (amount: number) => (
[...Array(amount).keys()].map((idx) => ({
idx: idx + 1,
stockName: `stock #${idx + 1}`,
price: Math.random(),
} satisfies Stock))
);
const currentStocksByIdx = new Map<Stock['idx'], Stock>();
let stocksTree = (
generateStocks(50_000).reduce((result, item) => {
currentStocksByIdx.set(item.idx, item);
return result.insert(item.price, item);
}, createRBTree<number, Stock>())
);
const updateStock = (updatedStock: Stock) => {
// we need to get the previous price to update the tree node
// time complexity: O(1)
const cachedStock = currentStocksByIdx.get(updatedStock.idx);
if (cachedStock) {
// time complexity: O(log n)
stocksTree = stocksTree.remove(cachedStock.price);
}
// respecitvely – update map to contain the updated price
// time complexity: O(1)
currentStocksByIdx.set(updatedStock.idx, updatedStock);
// time complexity: O(log n)
stocksTree = stocksTree.insert(updatedStock.price, updatedStock);
// total complexity: O(2 log n + 2) ~= O(log n)
};
console.time();
updateStock({
...currentStocksByIdx.get(25_000)!,
price: Math.random()
});
console.timeEnd();
Yeah, it's a bit messier, no argument there... but we've cranked up the speed significantly. 🔥 On my machine, updates now clock in at around 0.25ms, which is a solid 20x improvement and scales way better than the earlier approach. Need to apologize for assuming stock prices couldn't duplicate. I was just trying to keep things as straightforward as possible, sometimes simplicity wins, even if it bends reality a bit.
When arrays fail – trees save the day
Here's the bottom line: if you're dealing with data that needs to be traversed by specific ranges, or you've got to keep it neatly sorted, binary trees might just save the day. This is worth remembering anytime you're stuck working with data like that and your usual array methods feel like they're crawling. It's especially true when you're working with frequent updates for the UI or dealing with numeric parameters that need to be matched quickly. Sometimes, trees just do it better.
Performance Fixes You'll Pretend Were Hard
There's no point in diving into complex algorithms like KD trees or Dijkstra's. Let's be real: most frontend developers won't need them. And even if we did, the tools we use are already handling it for us. Overcomplicating things is a waste of time.
The Pareto principle is where it's at: focus on the 20% of optimizations that solve 80% of your app's performance problems. These are the simple fixes that tackle the biggest bottlenecks without turning your code into a maze. The basics often do the job just fine.
In the end, it's not about showing off how much you know. Stick to the changes that actually make a difference, and leave the fancy stuff for someone else. Users don't care about algorithms, they just want things to run fast.
Keep it simple, focus on what matters, and remember: sometimes the best solutions are the ones that don't require overthinking – instead, just get it done.